
深度学习是计算机视觉中的一项突破性机器学习技术。它从用户提供的训练图像中学习,并可以为各种图像分析应用程序自动生成解决方案。然而,它的主要优势在于,它能够解决许多过去传统、基于规则的算法难以解决的应用程序。最值得注意的是,这些包括检查形状或外观高度可变的物体,例如有机产品、高度纹理的表面或自然的户外场景。此外,当使用现成的产品(例如我们的 Deep Learning Add-on)时,所需的编程工作量几乎减少到零。另一方面,深度学习正在将重点转移到处理数据、处理高质量图像注释和试验训练参数上——这些元素实际上往往占用了当今应用程序开发的大部分时间。
典型应用包括:
检测表面和形状缺陷(例如裂纹、变形、变色);
检测异常或意外的样品(例如缺失、破损或低质量的零件);
根据预定义类别(即分拣机)识别对象或图像;
图像中多个对象的位置、分割和分类(i.e. bin拾取);
产品质量分析(包括水果、植物、木材和其他有机产品);
关键点、特征区域和小物体的位置和分类;
光学字符识别。
深度学习功能的使用包括两个阶段:
训练 – 根据从训练样本中学到的特征生成模型,
推理 – 将模型应用于新图像以执行实际的机器视觉任务。
与传统图像分析方法的区别如下图所示:

深度学习工具概述:

异常检测-此技术用于检测异常(异常或意外)样本。它只需要一组无故障样本来学习模型 外表正常。或者,可以添加几个错误样本以更好地定义可容忍变化的阈值。这个工具特别有用 在难以指定所有可能的缺陷类型或根本无法获得阴性样本的情况下。此工具的输出为:分类结果(正常或有缺陷)、异常分数和图像中异常的(粗略)热图。


特征检测(分割)-该技术用于精确分割一类或多类像素特征。属于每个类的像素必须由用户在训练步骤中标记。这种技术的结果是每个类的概率映射数组。
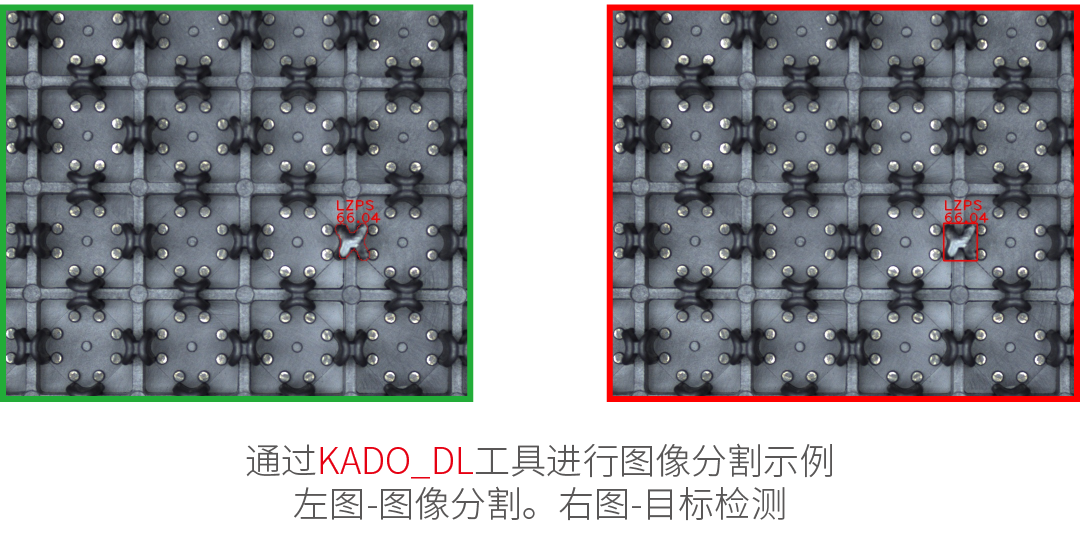

对象分类-此技术用于使用用户定义的类之一识别选定区域中的对象。首先,需要提供一组标记图像的训练。该技术的结果是:名称检测到的类和分类置信度。


实例分割 – 此技术用于定位、分割和分类图像中的一个或多个对象。训练要求用户绘制与图像中的对象对应的区域,并将其分配给类。结果是检测到的对象列表–及其边界框、掩码(分段区域)、类ID、名称和隶属度概率。


字符识别–此技术用于定位和识别图像中的字符。结果是找到的字符列表。
















